
Zenoh-Flow was the concluding episode of Zenoh’s webinar series “Taming the Dragon” released recently and available on ZettaScale’s Youtube channel. In case you haven’t watched the webinar (which you should definitely do!), click here! This blog provides additional insights about Zenoh-Flow: its origin, motivating use-cases, and upcoming features.
Data Flow Programming
As we explained in our webinar, Zenoh-Flow is Zenoh’s native Data Flow Programming framework, offering a common abstraction applicable from the Data Center down to the microcontroller.
Data Flow Programming is not a new concept. The term was first coined by Jack B. Dennis and David P. Misunas in 1961 (pdf) when they designed their data-flow processor. Gilles Kahn made another substantial contribution to the field in 1973 (pdf) by formalizing the concept for parallel programming in general.
To summarize, Data Flow Programming is a programming paradigm in which applications are organized as a directed graph of nodes, where each node represents a computational unit and each arc a stream of data.
This programming model is at the foundation of many application domains, such as Analytics, Autonomous Driving and Robotics. For instance in these latter cases, we can find multiple sensors sending data to an object detection unit, which in turn sends its results to a path planning unit, which eventually sends commands to the engine of the robot or the autonomous car. There is a clear flow of data that goes from the sensors to the motors.

Example of Data Flow inside a Robot
A complementary consideration is that applications are no longer contained to a single host or device, they span across the whole Cloud-to-Thing spectrum. We thus need to interconnect their different parts and preferably do so as transparently and efficiently as possible. Two properties where Zenoh really shines!
Zenoh-Flow overview
Hence, based on this previous analysis, when designing Zenoh-Flow we wanted for it to:
- Work seamlessly across the continuum: through location-transparent addressing, automatic deployment of nodes and a unified abstraction.
- Be explicit rather than implicit: the application graph is known beforehand and does not depend on runtime decisions.
- Be performant: it should boast minimal overhead and automatic context-dependent optimisations.
- Favor fast-development processes: developers should reuse nodes, compose them, or disseminate them through distributed marketplaces.
To achieve these requirements, we center the development of a Zenoh-Flow application around two axis:
- Descriptors: they describe the structure of the data flow, the nodes it contains (1, 2) and their interconnections.
- Nodes implementations: they contain the business logic of the different nodes composing your application. Zenoh-Flow differentiates 3 types of nodes:
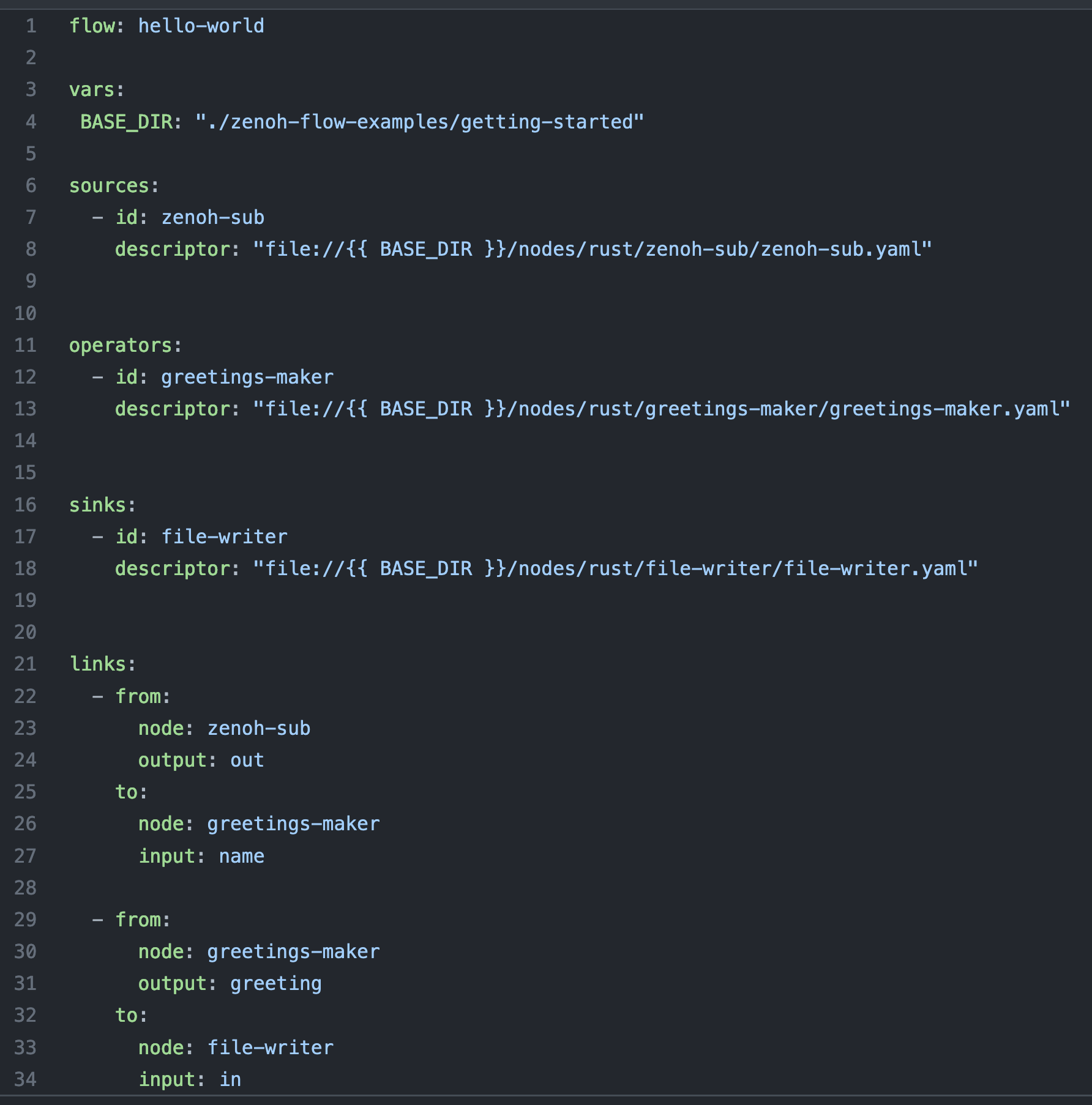
Data Flow descriptor
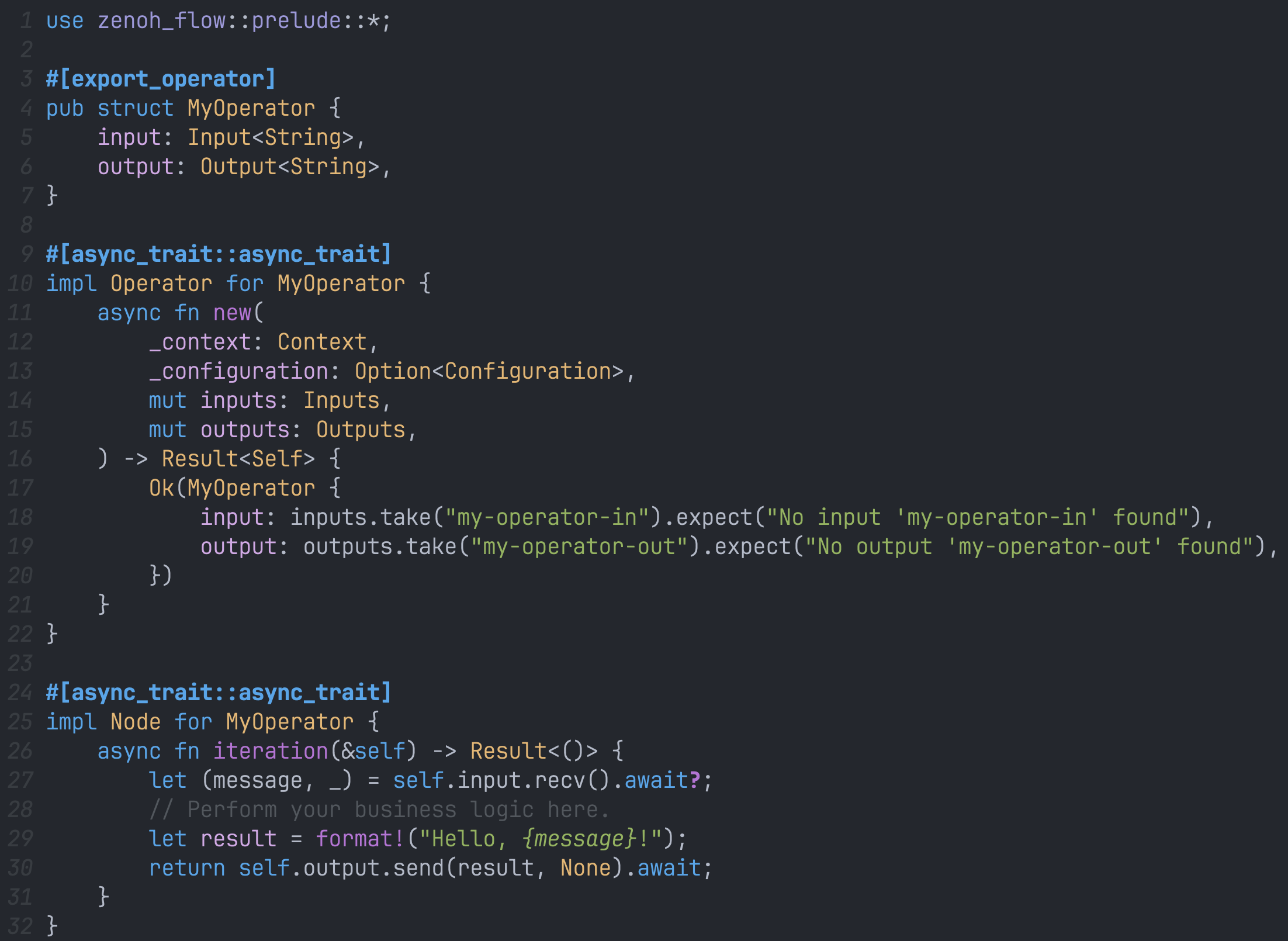
Zenoh-Flow Rust API
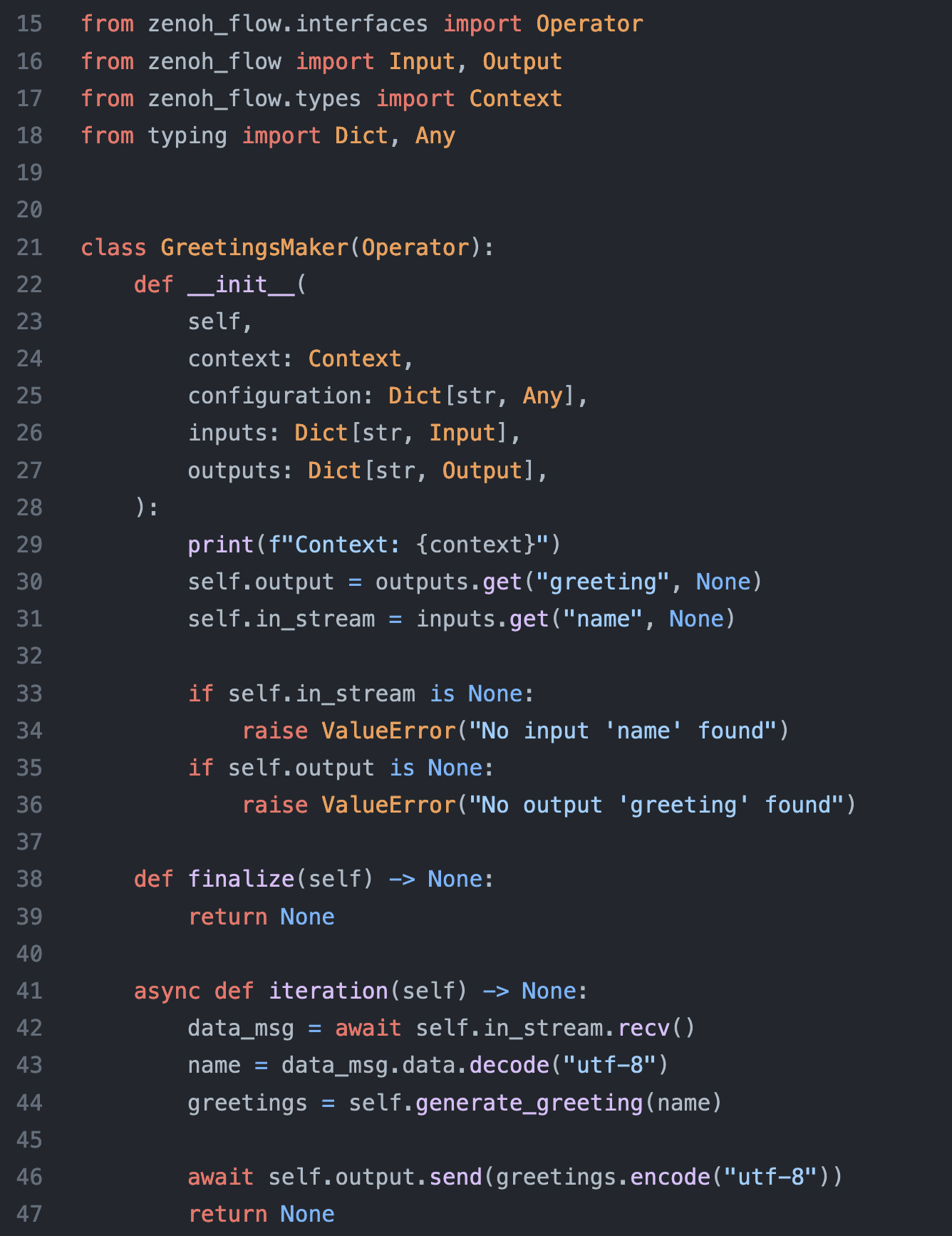
Zenoh-Flow Python API
As illustrated above, Zenoh-Flow currently supports nodes written in Rust and Python.
Once in possession of the descriptors and the node implementations, our command line tool zfctl will allow you to deploy your application in one simple line:
$ zfctl launch my-flow.yaml
That’s it!
Under the hood, a Zenoh-Flow runtime will parse this data flow descriptor and, together with all the runtimes involved, create the required connections as well as fire up the different nodes. All without requiring any (additional1) intervention from the user on the target devices.
As we mentioned performance earlier, let’s take a quick look at an optimisation Zenoh-Flow does transparently. Depending on the localisation of the nodes, different streams will be used to exchange data: if two nodes are located on the same runtime, a channel will be used instead of a Zenoh publisher / subscriber pair. This allows for lower latency as well as zero-copy.
Another noteworthy property of Zenoh-Flow is data isolation: a unique identifier is generated for each instance of a data flow which is then used to separate the publishers and subscribers. Each data flow will only receive the data it is supposed to. Notice that a lack of isolation, as is the case with some mainstream robotic frameworks, can induce unwanted communications which can then disrupt your application.
This illustrates how Zenoh-Flow allows users to focus on what matters most to them, their business logic. All the nitty gritty details, which are often a source of mistakes and frustrations, are handled by Zenoh-Flow.
Example applications
If you want to try out Zenoh-Flow, we provide simple data flows in our example repository: a Hello, world! and a Period miss detector that directly interact with Zenoh.
We also provide an implementation of the Montblanc testbed for robotics:
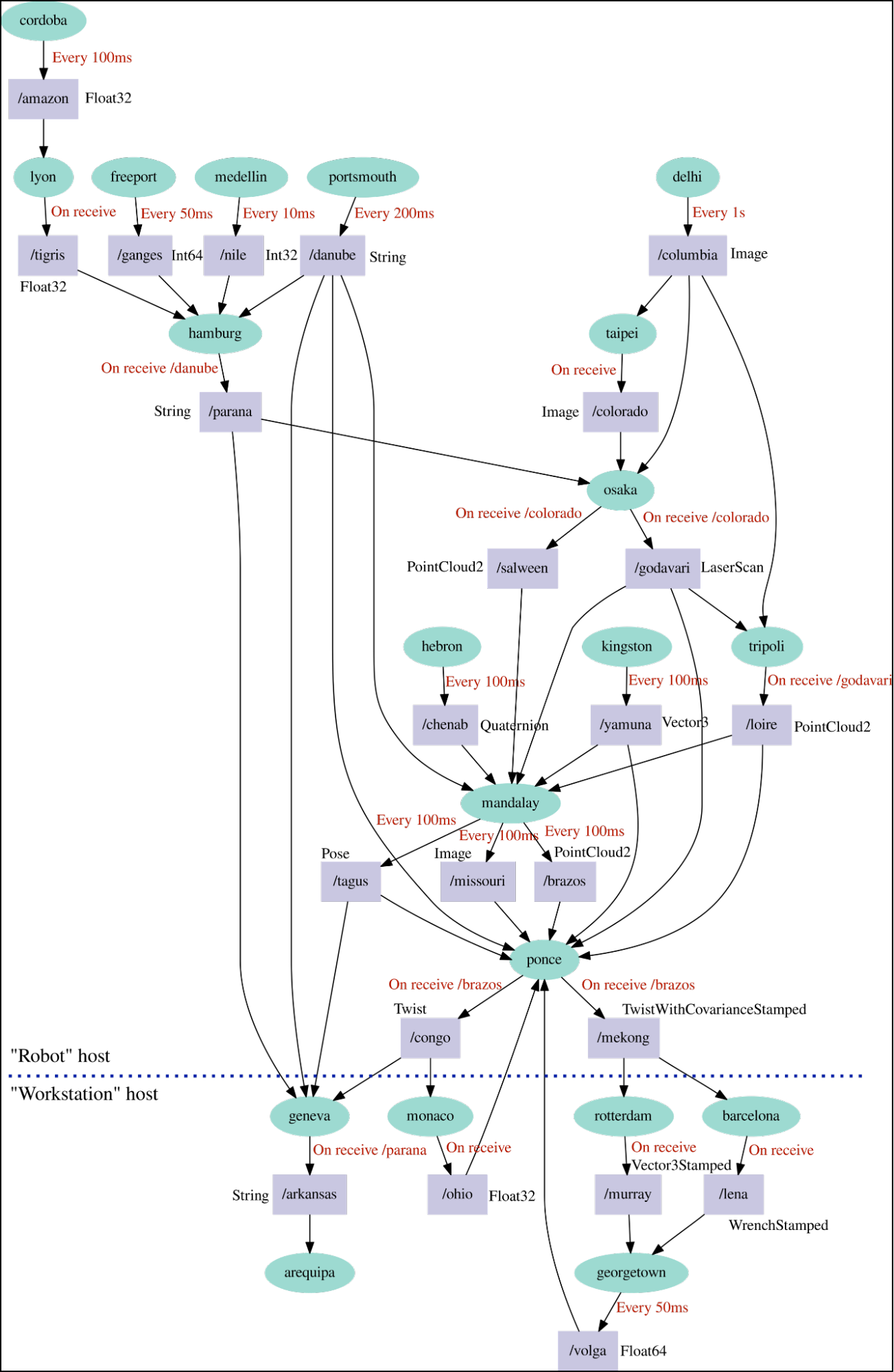
Montblanc robotics testbed
As one can see, Zenoh-Flow handles complex graphs. It also already provides several benefits:
- the flow of data is known ahead of the instantiation of the graph, i.e., no dynamic “discovery” is required,
- Zenoh-Flow ensures the unicity of the key expressions, there will not be any collisions and each node will only receive the data it declared in its descriptor.
Our main test application is a port of UC Berkeley’s ERDOS - Pylot autonomous driving pipeline, called STUNT. As it stands, STUNT uses the perfect perception: we receive the exact information of the car and its environment from the simulator and, based on these, we compute how much steering and acceleration to give. The data flow is as follow:
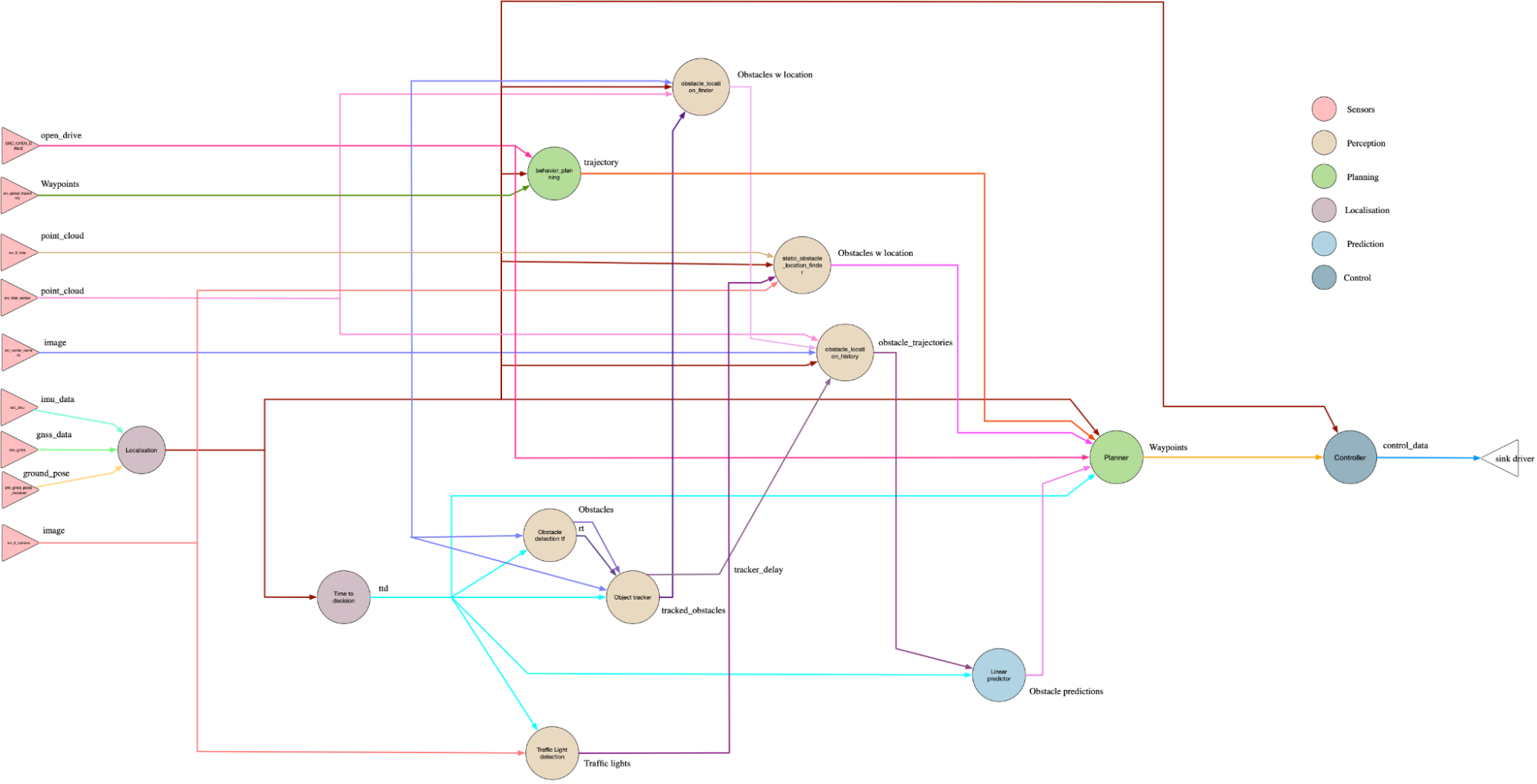
STUNT Data Flow
We then deployed it on our infrastructure and obtained the following recording:

Our first measurements show notable improvements in the execution time of the pipeline. A concrete consequence was that, to obtain the above video, we did not need to stop the simulator between each frame and wait for a command for the car. The pipeline was running in “real simulated time”.
The following figures show the execution time needed to perform different scenarios (pedestrian avoidance, slow car overtake, lane change) in their entirety. As one can see, the execution time with Zenoh-Flow is noticeably reduced. We want to slightly nuance these last results as they were obtained with earlier versions of both ERDOS and Zenoh-Flow.
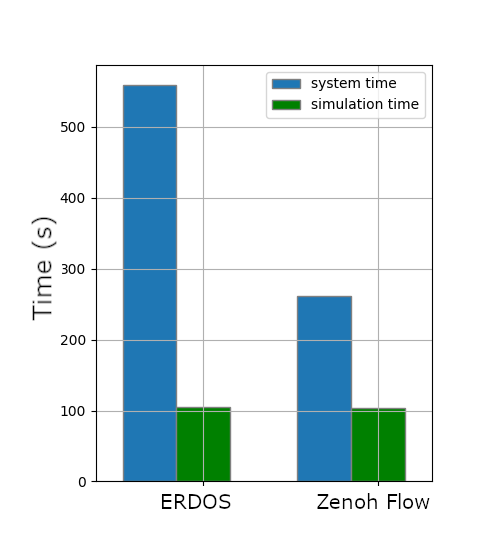
Pedestrian avoidance
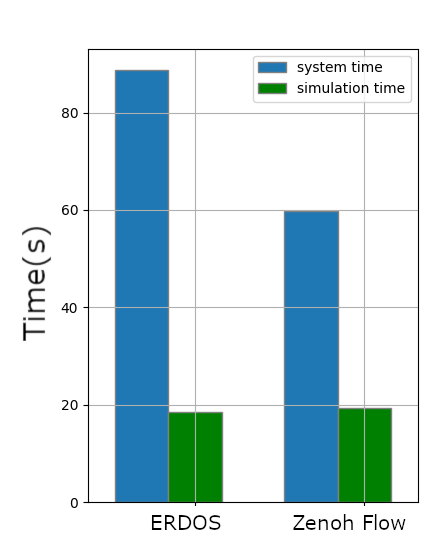
Slow car overtake
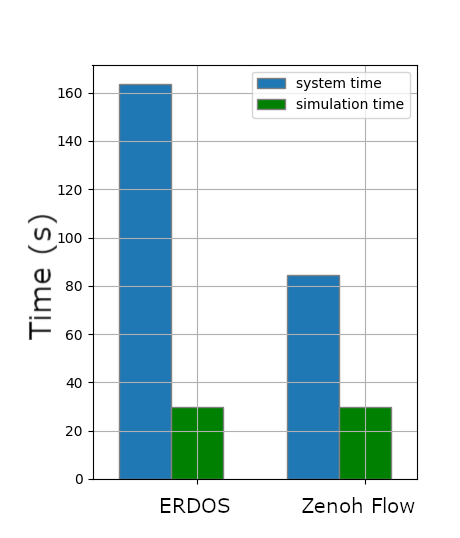
Lane change
What is next for Zenoh-Flow?
Building on these promising results, here is what we have planned for Zenoh-Flow.
Our next step will be to further the integration with Zenoh. As shown in the examples, in order to subscribe (resp. publish) on a key expression a Source (resp. Sink) must be implemented. This tighter integration will provide a builtin implementation of a Source / Sink directly derived from the data flow descriptor.
Next, we plan to improve the developer experience: the ability to test nodes in isolation, better logging and error messages.
In the mid term, we want to (i) provide a marketplace API to favor the reuse of nodes and (ii) explore how to better orchestrate the execution of nodes to further improve the performance of Zenoh-Flow (but not only…!).
Having a marketplace would yield two main benefits: facilitating the reuse of nodes and removing the need to upload the nodes implementation where they should be deployed.
Better orchestrating the execution of the nodes is possible because Zenoh-Flow knows the flow of data in the application, before it is instantiated. Armed with this knowledge, we can leverage known scientific results to optimize the execution. What makes this even more interesting is that we believe it would unlock other uses: behavior trees are a field we are looking into!
We are also planning on having a graphical user interface to facilitate the creation of data flows. That’s however on a more long term plan and will be the object of a dedicated blog post!
We hope that this introduction to Zenoh-Flow has proven to be interesting and, as usual, if you want to give some feedback or interact with us, please use the links in the footer.
The current version of Zenoh-Flow requires you to upload, beforehand and on each device, the implementation of the nodes they will run. As we explain later, this is a constraint we are working on removing! ↩︎