
Zenoh Storage Gets a Boost: Empowering Storage with S3 Integration
July 17th, 2023 -- Paris
As we happily announced on the blog post for the Zenoh 0.7.0-rc release (Zenoh Charmander is coming to town), we now provide enhanced backend storage capabilities with the new AmazonS3/MinIO backend implementation.
This was a requested feature that originated within our community on Discord which soon made its way into the roadmap.
The S3 backend can be installed by downloading the package from https://download.eclipse.org/zenoh/zenoh-backend-s3/latest/. The source code can be found in our eclipse-zenoh repository: https://github.com/eclipse-zenoh/zenoh-backend-s3. Inside you will find a README with detailed instructions on how to set up this backend for both Amazon S3 and MinIO.
Contents
In this blog post we’ll go through the S3 backend, explaining what’s the conception behind a backend, how the S3 backend fits into it, how to configure it and what are some of its limits and considerations to take when using this backend.
Table of contents:
Zenoh Backends
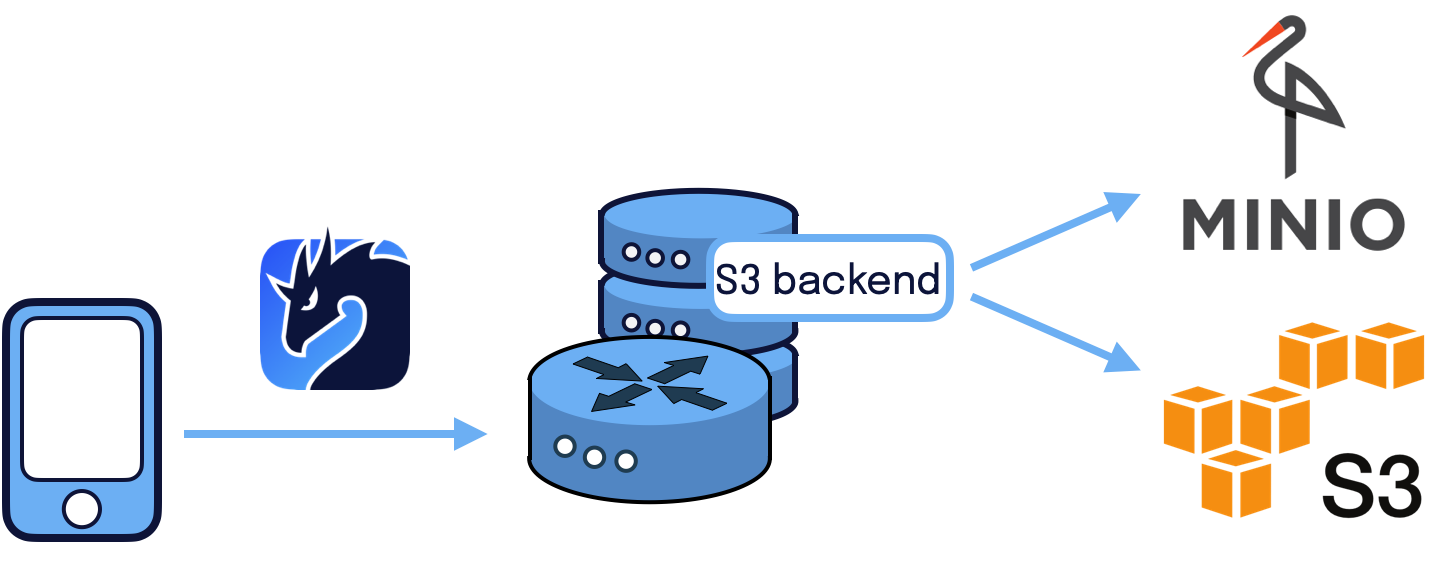
You may ask yourself “what is a backend?”. Well, in Zenoh a backend is a storage technology allowing to store the key/values publications made via Zenoh and return them on queries. Different storage technologies allow storing key/values based on different use cases.
At the moment we had three backend systems:
- InfluxDB: a time series data platform userful for developers to build IoT, analytics and cloud applications
- RocksDB: a high-performance persistent key-value store for fast storage environments
- FileSystem: this backend relies on the host’s file system to implement the storages.
AmazonS3 joins this list with the capability of storing the data on a cloud storage service.
It will boost our storage capabilities, especially when it comes to object oriented storage. So far the only way to work with object storages was using the FileSystem backend which was designed to be a simple storage option constrained into the host’s filesystem. It is a backend that also lacks many of the mechanisms a cloud storage provides regarding security, data availability and performance, and is not very scalable either.
Our users needed the possibility to interact with an object storage technology that could easily be set up on the cloud, that would already provide performance, security and data availability and that could be scalable. Amazon S3 reunited all of these conditions and was immediately proposed, as up to today it’s been a proven technology with a broad adoption in the systems industry.
Features
S3 storage
Amazon S3 (which stands for Simple Storage Service) provides object storage capabilities through Amazon Web Services, offering “industry-leading scalability, data availability, security, and performance”.
This backend allows us to:
- store values as files/objects in an S3 bucket
- create a bucket
- reuse an existing bucket
- put values on the storage, that is to create or update a file in the storage with the value specified, under the path provided by the key expression
- query values / files with:
- concrete key expressions
- key expressions containing wild cards (‘
\*’ and ‘\*\*’) (which will return the values of the files whose path match the key expression)
- delete files
- delete the storage
Compatibility with MinIO
MinIO is an open source multi-cloud object storage that offers high-performance and is an S3 compatible object storage. We developed the backend in order for you to be able to either choose AmazonS3 or MinIO depending on your use cases. There may be many factors for you to decide on one over the other. One to consider is the amount of interactions with the storage, as with Zenoh, you can receive thousands of requests to put or retrieve data from a storage, which can have an impact on the pricing of your storage in case of using Amazon S3.
TLS support
AmazonS3 provides HTTPS support per se, but if you set up your own S3 instances using MinIO, you’ll probably want to secure the connection using TLS. For that you need to specify the certificates that will allow you to authenticate your servers. That certificate from the certificate authority can be specified in the configuration file.
Configuration
The example configuration file below can also be found in our repository. In it we have parameters for ‘volumes’ and ‘storages’.
{
"plugins": {
"storage_manager": {
"volumes": {
"s3": {
// This field is mandatory if you are going to communicate with an AWS S3 server and
// optional in case you are working with a MinIO S3 server.
"region": "eu-west-1",
// Endpoint where the S3 server is located.
// This parameter allows you to specify a custom endpoint when working with a MinIO S3
// server.
// This field is mandatory if you are working with a MinIO server and optional in case
// you are working with an AWS S3 server as long as you specified the region, in which
// case the endpoint will be resolved automatically.
"url": "https://s3.eu-west-1.amazonaws.com",
// Optional TLS specific parameters to enable HTTPS with MinIO. Configuration shared by
// all the associated storages.
"tls": {
// Certificate authority to authenticate the server.
"root_ca_certificate": "./certificates/minio/ca.pem"
}
}
},
"storages": {
// Configuration of a "demo" storage using the S3 volume. Each storage is associated to a
// single S3 bucket.
"s3_storage": {
// The key expression this storage will subscribes to
"key_expr": "s3/example/*",
// this prefix will be stripped from the received key when converting to database key.
// i.e.: "demo/example/a/b" will be stored as "a/b"
"strip_prefix": "s3/example",
"volume": {
// Id of the volume this storage is associated to
"id": "s3",
// Bucket to which this storage is associated to
"bucket": "zenoh-bucket",
// The storage attempts to create the bucket, but if the bucket already exists and is
// owned by you, then with 'reuse_bucket' you can associate that preexisting bucket to
// the storage, otherwise it will fail.
"reuse_bucket": true,
// If the storage is read only, it will only handle GET requests
"read_only": false,
// strategy on storage closure, either `destroy_bucket` or `do_nothing`
"on_closure": "destroy_bucket",
"private": {
// Credentials for interacting with the S3 bucket
"access_key": "AKIAIOSFODNN7EXAMPLE",
"secret_key": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"
}
}
}
}
},
// Optionally, add the REST plugin
"rest": { "http_port": 8000 }
}
}
In our conception of what an S3 storage is, each storage is associated with an S3 bucket, while a volume is associated with a server. A volume can be associated with many storages, which means that all the s3 buckets are going to be stored on the same server.
The volume configuration required is limited to specifying where the server is going to be located (if you are using Amazon S3 you need to specify only the region, while when using MinIO you need to provide an url) and eventually the TLS certificate path. All the storages associated with it will share the same configuration.
Within the storage configuration, we specify the key expression, the name of the bucket, the credentials needed to access it, some policies related to the creation of the storage and its read-write permissions, etc… More detail is provided in the example config file.
Considerations
Keep in mind that this S3 backend is still a work in progress and some extra work on it is to be expected.
There are a couple things to consider when using this backend at this stage, some related to how MinIO and AmazonS3 work and some related to the status of the development of this backend.
Same name files and directories
Regarding the differences between MinIO and AmazonS3, MinIO is “S3 compatible”, which doesn’t mean it works identically.
One difference we noted during the development emerged from the question: what if we put a value under the key ‘a/b’ and later another one under a/b/c. With Zenoh one may expect this to be possible; Zenoh allows you to publish a value under a/b/c or under a/b, receivers subscribed to a/\*\* for instance should be able to receive both events, independently if the listener is a storage or not.
So how does the system behave when dealing with this situation?
└── a
├── b
│ └── c
└── b
Performing a publication under a/b and later under a/b/c (or inversely) means we’ll have a directory with the same name as a file under the same location, under /a!
MinIO doesn’t permit such a behavior and will throw an error message when attempting to perform such a thing. However, Amazon S3 doesn’t complain at all! That is because Amazon S3 uses a flat namespace to organize its files and directories, while MinIO uses the file system hierarchy for storing (see this discussion for more info). With file systems we can not have a file with the same name as a directory at the same place. We had in fact stumbled with this issue when developing the file system backend some time ago, and had to develop a mechanism to allow this behavior and store the values for both events. However on this new S3 backend, a mechanism for this is not implemented for the moment, so you need to keep that into consideration when using this backend alongside MinIO at this stage.
Sample timestamps
We are not yet taking into consideration the timestamps of the samples, this may cause problems in some edge cases, for instance in the case we send a PUT immediately followed by a DELETE on the same key expression, it may happen that the DELETE operation gets to the storage earlier than the PUT, which would cause a file to be kept stored instead of being removed as intended, due to order issues. Taking the timestamps into account would have allowed us in this example case to discard the PUT operation, avoiding to corrupt the storage. This is yet to be implemented and an issue is already opened for it.
Replicas support
Replication is not yet supported from the Zenoh side. If we have two S3 backends subscribed to the same key expression and one goes momentarily down, when respawning it needs to fetch the data it missed from the other backend to synchronize. This is not yet implemented. We can, however, profit from the replication mechanisms both Amazon S3 and MinIO provide.
Another replication problem comes in when we want to have multiple but with different backends, for instance S3 and RocksDB. There is no workaround for this at the moment and it’s up to the user to manually take care of synchronization.
Aws-sdk-s3 library
Finally, this implementation relies on Amazon’s aws-sdk-s3 Rust crate, which is itself under development and clearly states: “Please Note: The SDK is currently in Developer Preview and is intended strictly for feedback purposes only. Do not use this SDK for production workloads.” So, you need to take that into strong consideration before making a production release.
As of today, the amazon’s engineering team that’s developing this crate is regularly publishing new versions of it. As a consequence, new versions of this backend are to be expected in the future in order to update the dependency versions.
What’s next!
This concludes our post on how to use S3 as a storage for Zenoh thanks to our recent implementation of the S3 backend.
Although it’s a work in progress, this first version of it already provides us with many functionalities. We can:
- take advantage of Zenoh’s virtues such as using key expressions for querying data from S3 storages
- secure our communications with the S3 storages with TLS
- use MinIO as an alternative to Amazon S3
There are nevertheless limitations we aim to tackle in the near future.
Stay tuned for updates and don’t forget to stay in touch with the Zenoh team on Discord and to propose new features on the roadmap.
