
Zenoh-Pico performance improvements
April 30th, 2025 -- Paris.
Improving Zenoh-Pico performance
Last year, after the long-awaited release of Zenoh 1.0 which included a unified C API with Zenoh-C and Zenoh-Pico, we decided to dedicate some time to measure and improve the performance and efficiency of Zenoh-Pico. These modifications were released with Zenoh 1.1 earlier this year and we present the results to you with this blog post.
What is Zenoh-Pico?
Zenoh-Pico is the lightweight, native C implementation of the Eclipse Zenoh protocol, designed specifically for constrained devices. It provides a streamlined, low-resource API while maintaining compatibility with the main Rust Zenoh implementation. Zenoh-Pico already supports a broad range of platforms and protocols, making it a versatile choice for embedded systems development.
The results
To measure performance, we have a standardized throughput test and a latency test which we run on a standardized machine (Intel Xeon E3-1275 @3.6GHz, 32GB DDR4, Ubuntu 22.04). For embedded measurements, we ran those tests on an ESP32-WROOM-32 dev board.
These tests produce a thousand measurements or so per payload size that we use to calculate the median value to then get the following graphs (note that the y-axis is log scale):
PC throughput client, TCP:
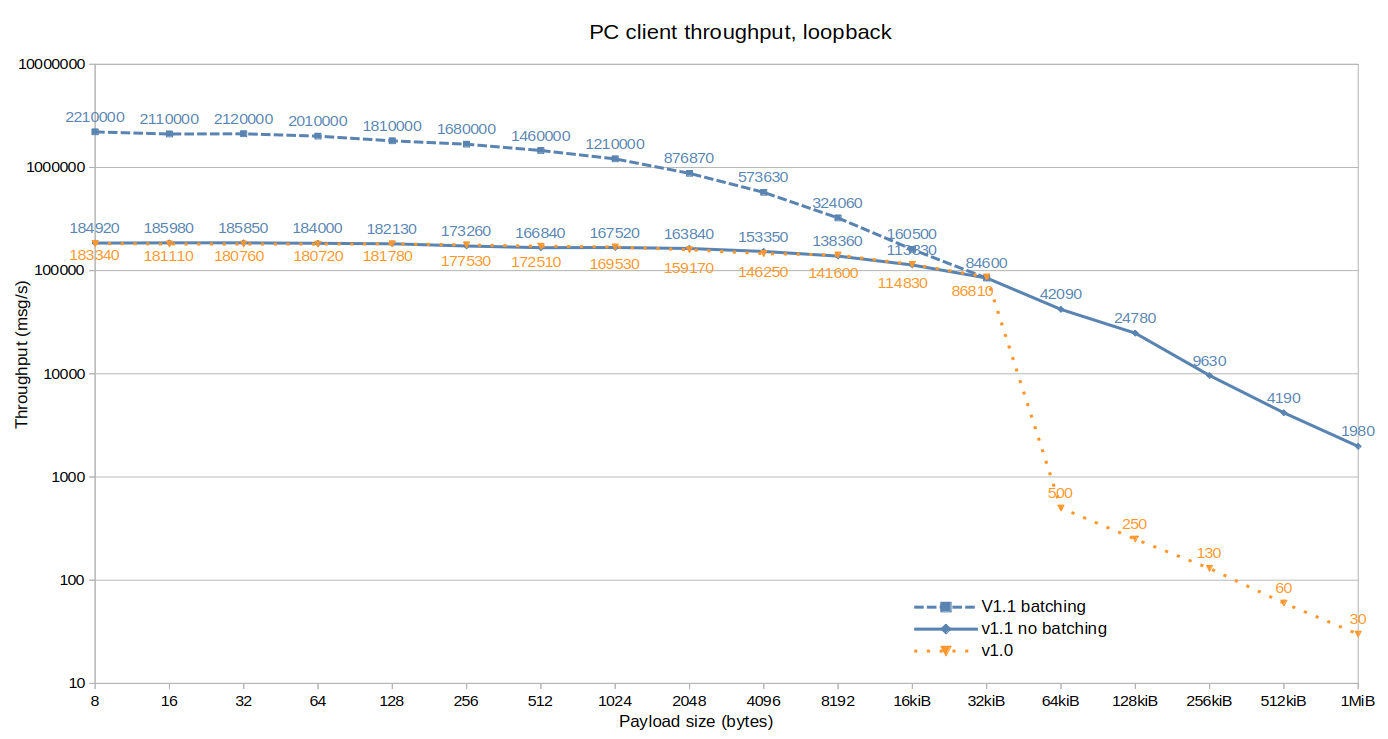
We see a massive (up to 100x) improvement in throughput for payloads over 32KiB, this is because packets of these sizes are fragmented on the network and we had an issue where their data was serialized byte-by-byte.
We also see a >10x improvement in throughput for smaller payloads when using manual batching (more info below) introduced in 1.1 as well.
Other than that there are no significant changes because client performance is limited by the router.
PC throughput peer to peer, UDP multicast:
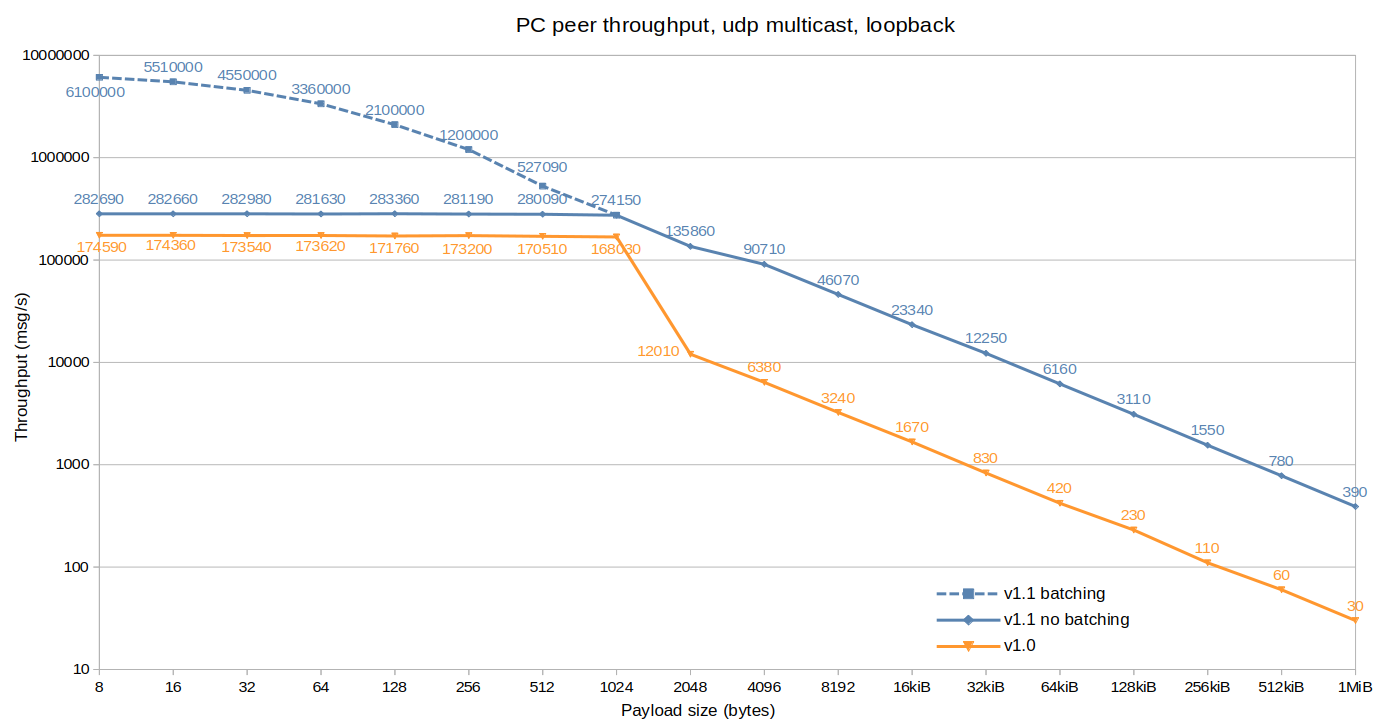
Peer to peer being not limited by router performance, we observe a bigger improvement on smaller payloads with batching (>20x), but a smaller one (>10x) for fragmented packets (>2KiB) because of UDP’s smaller packet size.
In addition, we observe a 60% throughput increase for the other payload sizes, that results from the general library optimization.
PC latency:
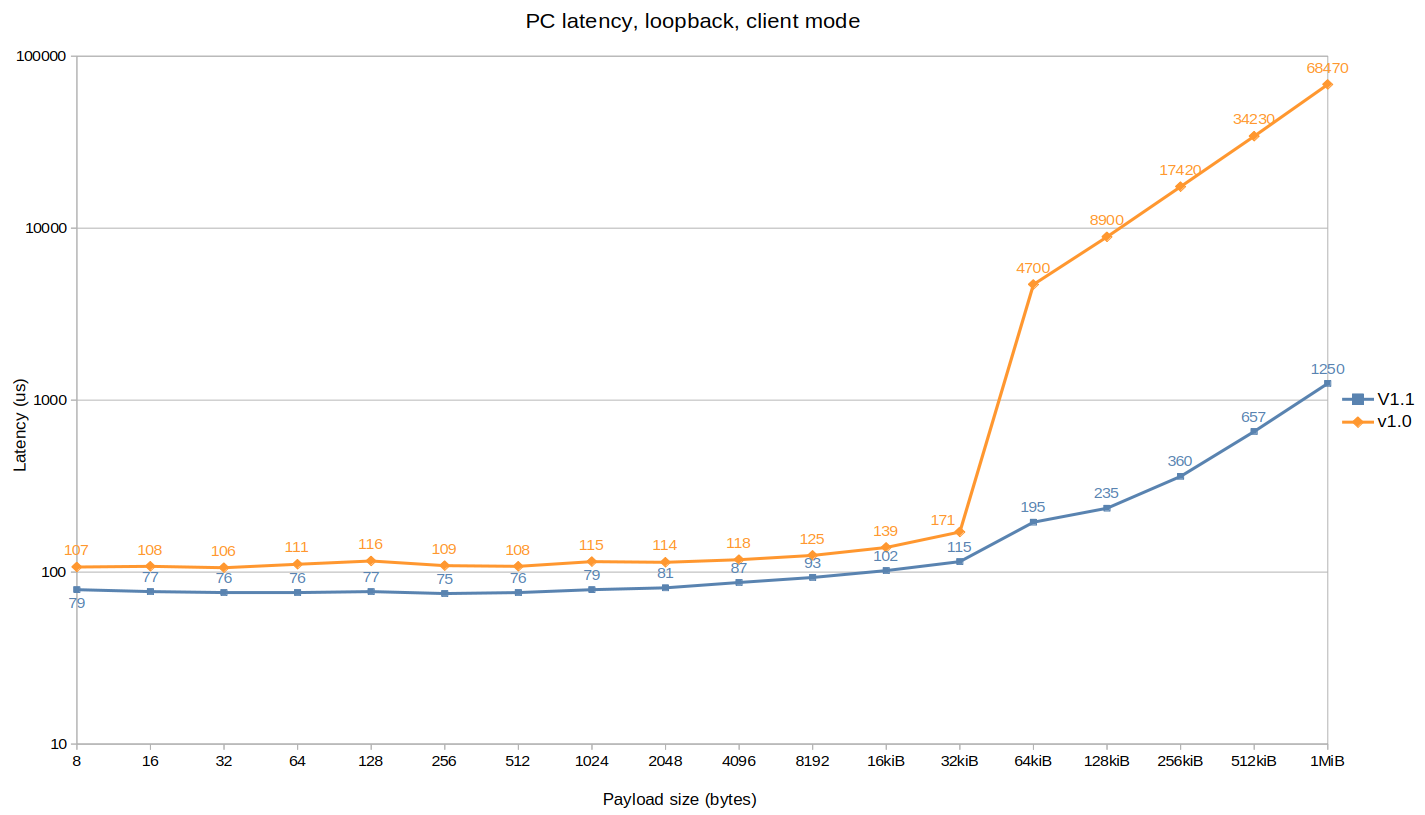
This plot shows a >50x enhancement on fragmented packets latency, again due to data copy improvement, but also a 35% boost across the board from the general library optimization.
Note that a big chunk of the latency value is due to the router (node to router hop + time to route the packet + router to node hop), and this value could be much lower using peer to peer TCP unicast.
Performance limitations/regime:
Before going into embedded results, let’s spend some time in understanding what are the limiting factors of performance.
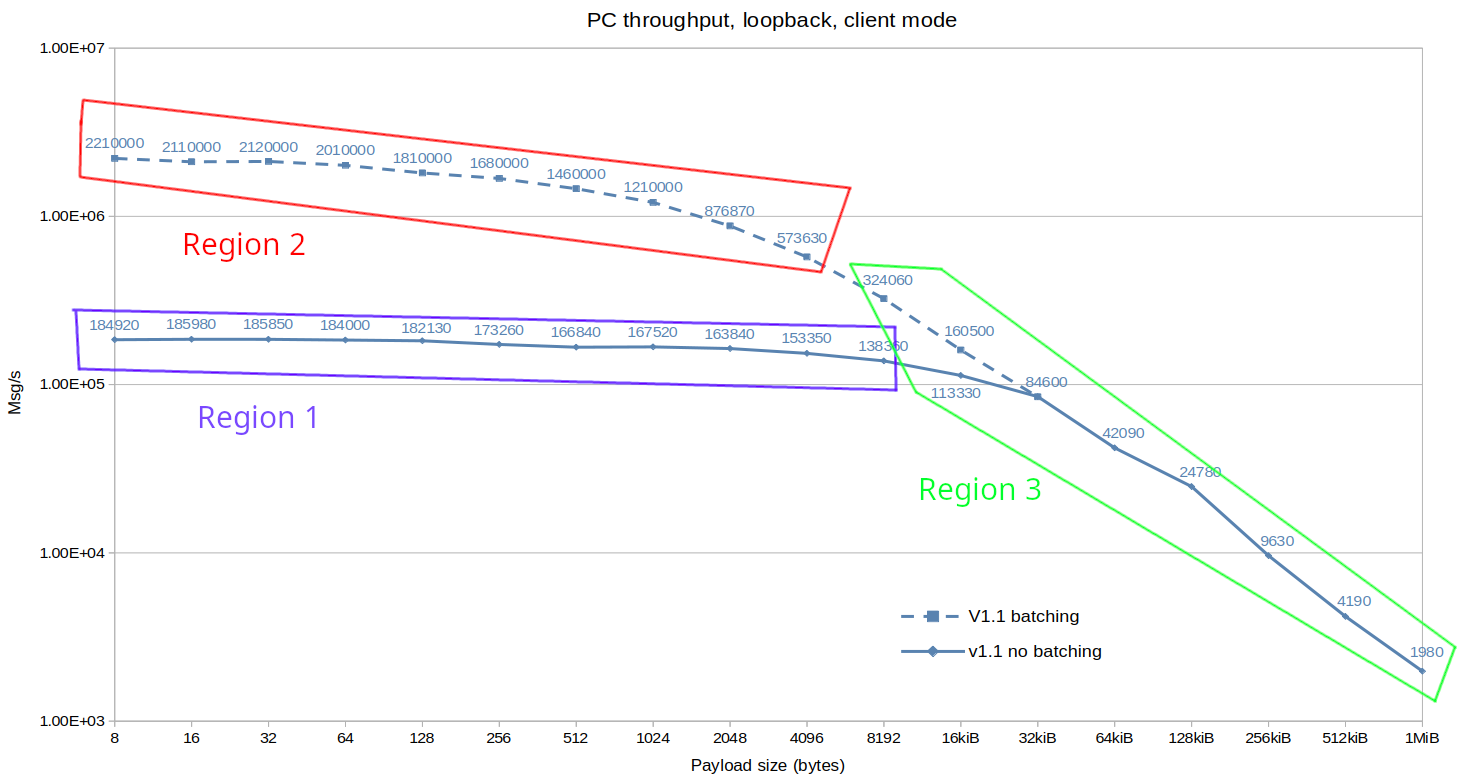
For throughput there are 3 distinctive regions:
- Region 1 is limited by network and syscalls, with
sendandrecvtaking more than 90% of the execution time. - Region 2 is limited by CPU speed / Zenoh-Pico performance, with TX taking slightly more CPU power than RX.
- Region 3 is limited by memory bandwidth, with
memcpytaking more and more of the execution time as payload size grows.
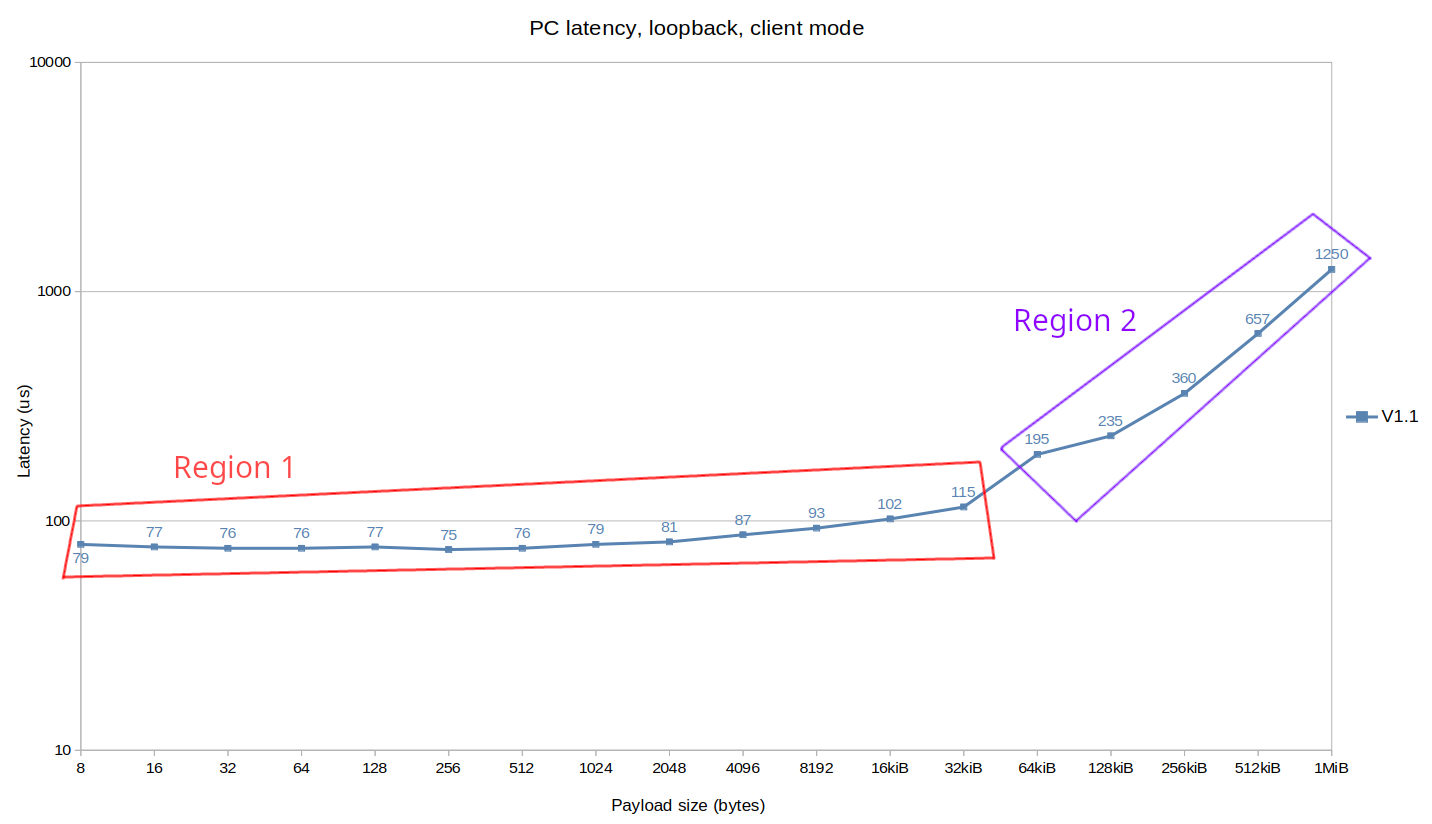
For latency there are 2 regions:
- Region 1 is limited by CPU speed / Zenoh-Pico performance.
- Region 2 is limited by memory bandwidth, similarly to throughput.
Embedded throughput:
Embedded systems being limited memory-wise, we limited payload sizes to 4KiB maximum which is still enough to observe fragmented packets behavior for 2KiB and 4KiB sizes.
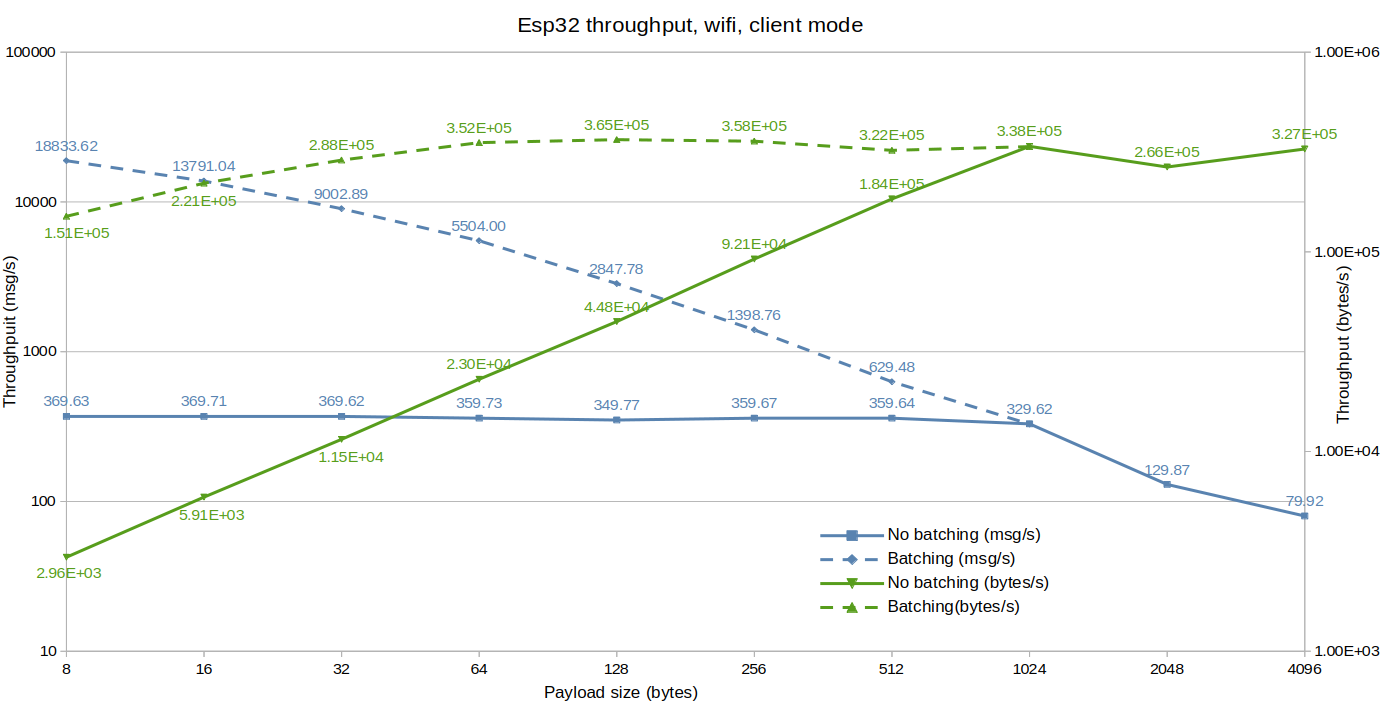
The ESP32 really benefits from batching with a >50x increase in throughput, which seems fair since we’re going through a much slower Wi-Fi interface compared to loopback that uses unix pipe.
Embedded latency:
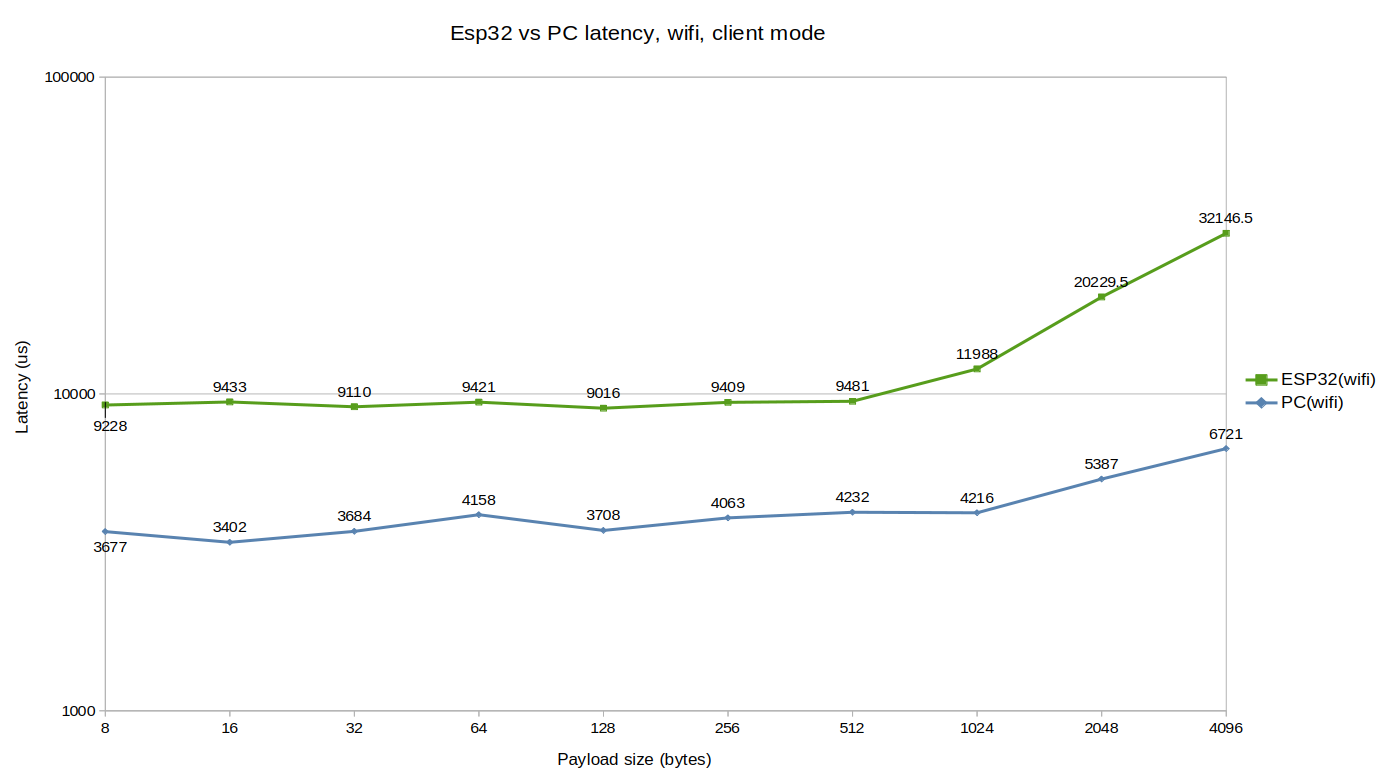
Latency values are in the ~10ms range mostly because Wi-Fi itself is slow as demonstrated by the ~4ms value observed on Zenoh-Pico PC latency measured on the same Wi-Fi network.
We do observe a big impact on latency when trying to send fragmented packets which should come from both Wi-Fi and ESP32 bandwidth limitation.
How performance was improved
To improve Zenoh-Pico performance, we traced it on PC using samply and the Firefox debugger to visualize the traces. That allowed us to detect choke points and parts of the code that could be improved.
As stated earlier, the most impactful changes were solving the byte-by-byte copy issue for fragmented packets and the introduction of the manual batching mechanism.
Besides that, we also streamlined a lot how the stack created, used and destroyed data to avoid redundant operations or unnecessary data copies. We also rationalized heap memory usage and fragmentation although these changes were not quantified.
Manual Batching
If you want to use Zenoh-Pico recently introduced manual batching you only have 3 things to know about:
zp_batch_start: Activate the batching mechanism, any message that would have been sent on the network by a subsequent API call (e.gz_put,z_get) will be instead stored until either the batch is full, flushed or batching is stopped.zp_batch_stop: Deactivate the batching mechanism and send the currently batched messages on the network.zp_batch_flush: Send the currently batched messages on the network.
Note that there are also cases where a batch will be sent if a message needs to be sent immediately, like when sending keep-alive messages or if the API pushes a message with the is_express QOS.
Examples:
In this example we will batch all the messages and send them in bulk to improve throughput. Every time the batch is full, it will be sent and the last one will be sent with the zp_batch_stop call:
zp_batch_start(z_loan(session));
z_owned_bytes_t p;
while (cnt < n) {
// Clone payload
z_bytes_clone(&p, z_loan(payload));
z_publisher_put(z_loan(pub), z_move(p), NULL);
cnt++;
}
zp_batch_stop(z_loan(session));
In this second example, another thread is responsible for sending messages and we want to batch them to avoid too many packets on the network, but we might want to limit latency, so we add a loop that will flush the batch periodically.
zp_batch_start(z_loan(session));
// Wait for other thread to add messages
while(is_running){
elapsed_us = z_clock_elapsed_us(&time_start);
// Flush buffer periodically
if (elapsed_us > 10000) {
zp_batch_flush(z_loan(session));
time_start = z_clock_now();
}
z_sleep_ms(1);
}
zp_batch_stop(z_loan(session));
Wrapping up
As you saw, we improved throughput and latency across the board, in some cases reaching a 100x increase.
We also introduced manual batching which, beside improving throughput of small messages, can be used to reduce power consumption in embedded devices by reducing network transmissions.
Now let’s talk briefly of our next big feature. As we hinted above, we are limited in client mode by the router both in throughput and latency, but client mode is currently the only way to use TCP links in Zenoh-Pico…
That was true until the newly introduced peer-to-peer unicast mode that we will present in a future blog post!