
Zenoh-Pico Peer to Peer Improvements
July 9th, 2025 -- Paris.
As hinted at in our previous blog post on Zenoh-Pico performance improvements, we’ve now introduced a long-requested peer-to-peer unicast mode for Zenoh-Pico! Let’s dive into how it works.
What is Zenoh-Pico?
Zenoh-Pico is the lightweight, native C implementation of the Zenoh protocol, designed specifically for constrained devices. It provides a streamlined, low-resource API while supporting all abstractions from Rust Zenoh: pub, sub and query, advanced pub/sub and so on. Zenoh-Pico already supports a broad range of platforms and protocols, making it a versatile choice for embedded systems development.
Peer-to-Peer Unicast
Until now, if you didn’t want to run a router with Zenoh-Pico nodes, you had to rely on multicast transport—an option that isn’t always feasible. Additionally, this method was limited to UDP, which lacks reliability.
Now, you can use TCP links to enable unicast peer-to-peer communication and enhance reliability in scenarios without a router. This advancement also improves throughput and latency, which we’ll discuss below.
This feature is supported and has been tested on all platforms, including FreeRTOS, ESP-IDF, Raspberry Pi Pico, Zephyr, Linux, and Windows. It is currently limited to TCP links, but may be extended to include UDP or Serial if there’s demand.
Architecture-wise, we use non-blocking sockets and I/O multiplexing to handle all connections on a single RX thread, plus an additional thread that listens on a socket and accepts incoming connections. For resource-efficiency reasons, peer-unicast nodes do not route traffic: every message received from a connected peer triggers our API, and every message created via our API is sent to all connected peers. This design allows for a single TX and a single RX buffer.
Examples:
Here is an example showing how to implement a 1:N (or N:1) communication graph:
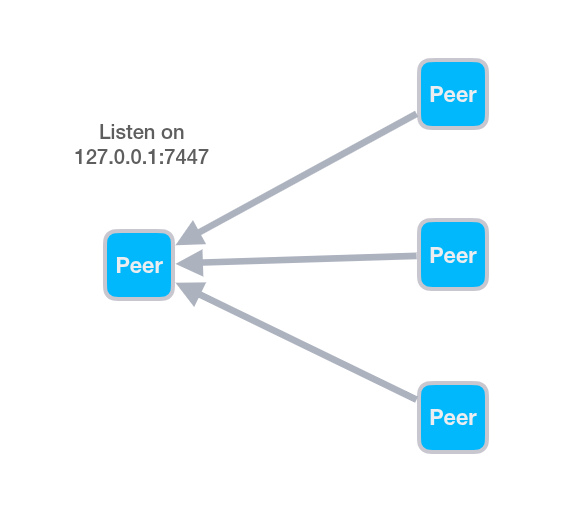
If we assume a single publisher connected to 3 subscribers, here’s how we could configure it:
./build/example/z_pub -l tcp/127.0.0.1:7447
./build/example/z_sub -e tcp/127.0.0.1:7447
./build/example/z_sub -e tcp/127.0.0.1:7447
./build/example/z_sub -e tcp/127.0.0.1:7447
To implement an N:N graph:
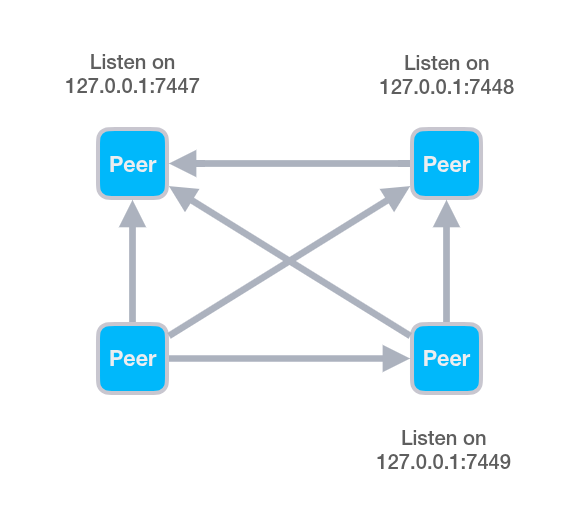
./build/example/z_pub -l tcp/127.0.0.1:7447
./build/example/z_sub -l tcp/127.0.0.1:7448 -e tcp/127.0.0.1:7447
./build/example/z_sub -l tcp/127.0.0.1:7449 -e tcp/127.0.0.1:7447 -e tcp/127.0.0.1:7448
./build/example/z_sub -e tcp/127.0.0.1:7447 -e tcp/127.0.0.1:7448 -e tcp/127.0.0.1:7449
Performances
Test Details
In addition to enabling peer-to-peer unicast, we improved general library CPU utilization, further boosting throughput and latency by approximately 10%. The tests were run on an Ubuntu 22.04 laptop equipped with an AMD Ryzen 7735U and 32 GB of RAM.
Configuration
Note that the Zenoh-Pico configuration used for testing deviates from the default. Here are the changes:
Z_FEATURE_SESSION_CHECKset to 0 (default 1): Skips the publisher’s session reference upgrade. This is risky if you use the publisher after closing the session.Z_FEATURE_BATCH_TX_MUTEXset to 1 (default 0): Allows the batching mechanism to hold the mutex, which can prevent the lease task from sending keep-alive, triggering connection closure.Z_FEATURE_RX_CACHEset to 1 (default 0): Activates the RX LRU cache. It consumes some memory to store results of key expressions that trigger callbacks—useful in repetitive, high-throughput scenarios.
Results
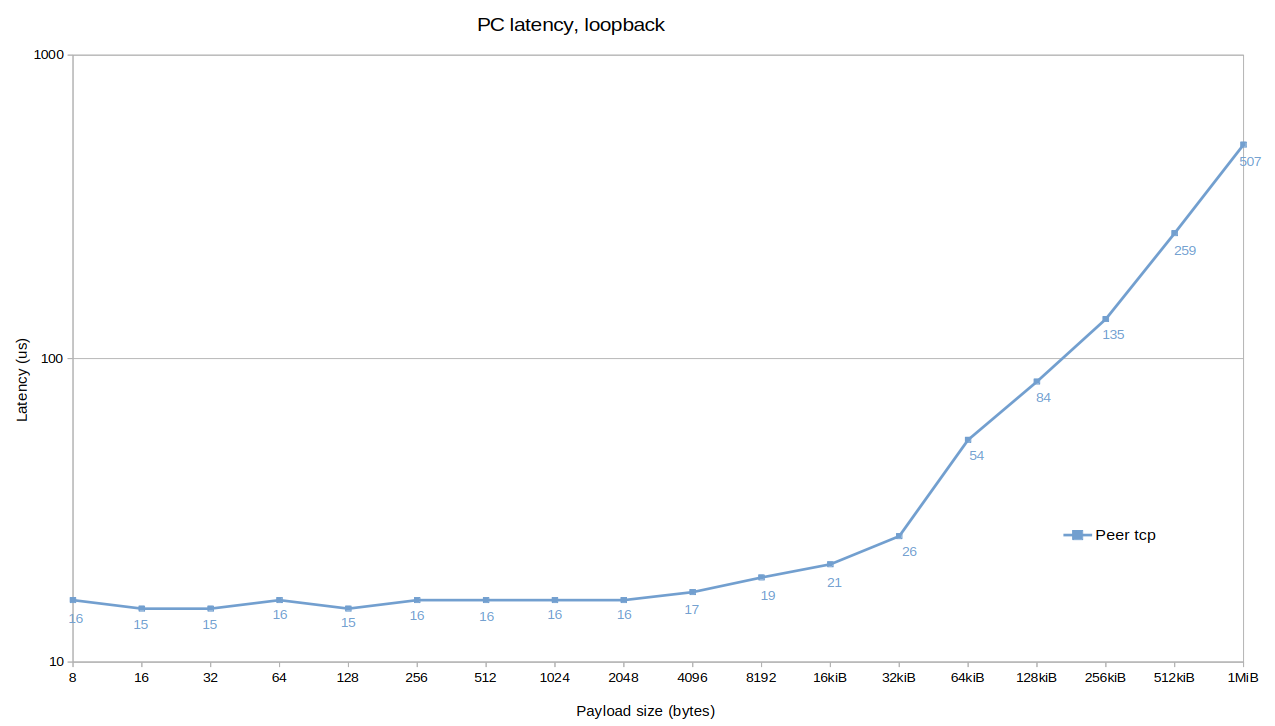
The round-trip time for packets below 16 KiB is under 20 µs—meaning a one-way latency of under 10 µs. Peer-to-peer unicast delivers up to 70% lower latency compared to client mode.
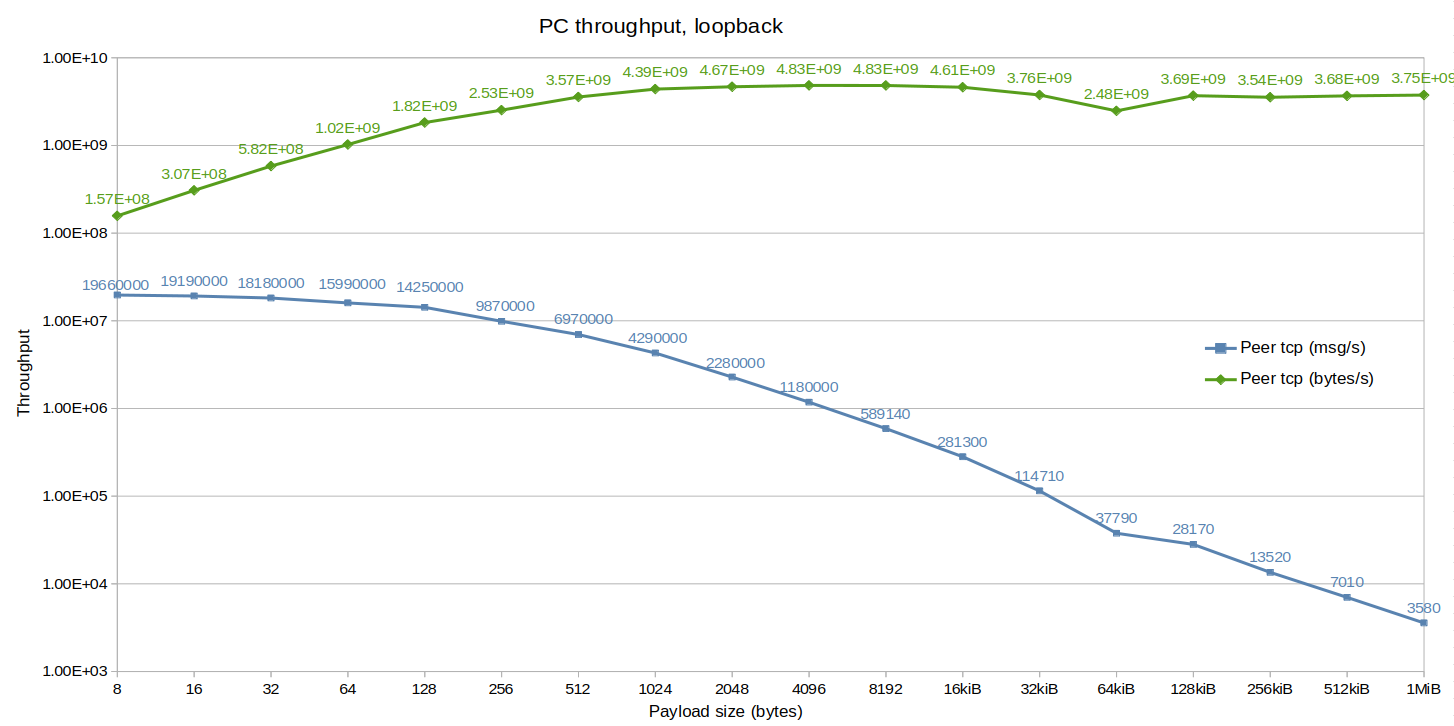
With up to 20 million messages per second for 8-byte messages, peer-to-peer unicast achieves over 4x the throughput of client mode for small payloads, and still improves performance by 30% for larger payloads.
Multicast Declarations
Alongside peer-to-peer unicast, we’ve implemented a multicast declaration feature. This allows multicast transport to:
- Use declared key expression, reducing bandwidth usage and improving throughput by up to 30% for small payloads.
- Implement write filtering, where publishers wait for at least one subscriber before sending messages.
This feature is disabled by default and can be enabled by setting Z_FEATURE_MULTICAST_DECLARATIONS to 1. It’s off by default because, for it to work correctly, all existing nodes must redeclare all key expressions and subscriptions whenever a new node joins the network—which can lead to congestion.
Memory Allocation Improvements
Previously, we discussed reducing dynamic memory allocations without providing measurements. We’ve measured allocations using heaptrack, and below you can see the results for the latest version:

Memory Breakdown:
The latest version of Zenoh-Pico includes some major performance and memory utilisation improvements, here are the latest numbers:
- Handled 84.4 million messages in 20 seconds (~4.2M messages/sec) — 15x throughput increase
- Peak memory usage: 101 kB — 91% less memory
- 118 allocations total, no per-message allocations thanks to ownership transfers and the RX cache — 99.9998% fewer allocations
- Defragmentation buffers now allocated on demand (not needed in this test)
- 100 kB: TX and RX buffers (50 kB each)
- ~50% of remaining allocations are from UDP scouting (can be eliminated with a direct router endpoint)
Since this test involved a single subscriber, no message copies were needed. With multiple subscribers, data copies would be required—but only for auxiliary data (like key expressions), as payloads are reference-counted.
Final Thoughts
This release brings substantial improvements to Zenoh-Pico’s flexibility and performance. Peer-to-peer unicast opens the door to more robust, scalable topologies without requiring a central router. And the combined enhancements in memory use, throughput, and latency make it a strong choice for high-performance embedded applications.